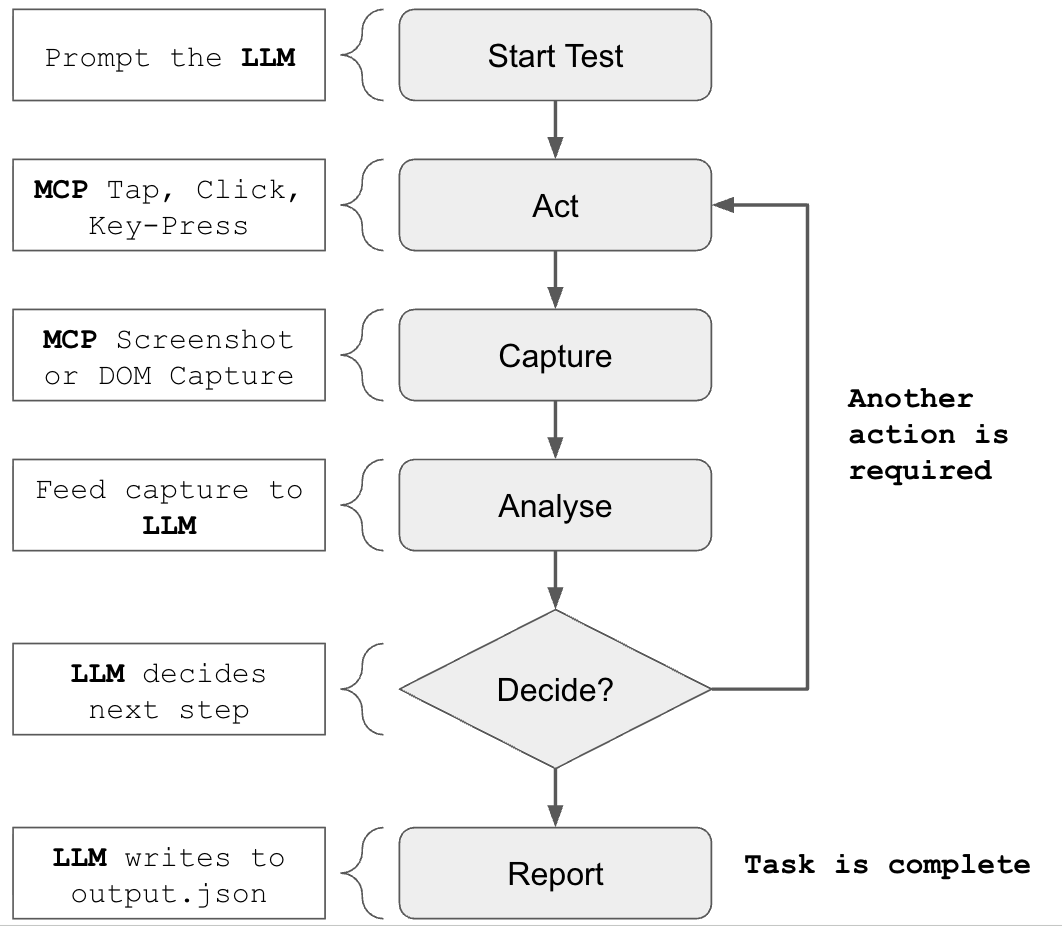
Introduction
The price of a financial instrument is not a fixed value. It is something that changes over time, driven by market forces. It’s quite common to view this as a chart that is updated as the price changes. In this post I will demonstrate how to sample an observable stream of prices and display the results in a real-time charting application.
To start with, lets consider a basic chart (aka tick chart), where we simply plot each movement in the underlying instrument.

This is fine when looking at small samples of data, but for volatile instruments, we might receive many prices per second. This can quickly become unwieldy. The computer might not have enough memory to plot days, months or years of prices. This will also show too much noise to the user, with constant price fluctuations that do not represent the sentiment of the market.
We need to sample the data in some way. The simplest approach is just to take the latest price at regular intervals. Rx has an operator that behaves in the exact manner – Sample.

This solution isn’t really suitable for technical analysis as we are diluting the information to an extent that it is difficult to deduce the overall market trend. Unfortunately analysts and traders are quite fussy! What they need is a chart that represents price performance for a specific period in a single point on the x-axis.
OHLC Charts
I’ve chosen this particular type of chart as it relatively simple. All we need to do is partition our data into regular time periods and determine four values;

We can then plot these quadruples as a price bar or candlestick. A “price bar” is a line representing the highest & lowest prices over a period of time, with “tick marks” showing the opening and closing price.

The candlesticks I mentioned are very similar, however the body is shaded to signify a positive/negative movement.

Lets see what our original chart would like like using price bars.

And now we can remove the original points…

I hope it’s clear how that was done. Additionally, it’s quite common to colour the bars so that a negative movements, between the open and close, are in red and positive movements are in a happy colour like blue or green. As I mentioned earlier this is essential for the candlestick variant of the chart. Ultimately we want to be able to build applications that plots real-time data like this;


Now that you know what we are building, lets work out how the Rx code is going to work. Hold on to your hat!
Generate
First up, we’re going to need a stream of observable prices to play with. I’d like my price stream to start at $5. Then every 10th of a second, I’d like to apply a random adjustment to the price.
var rand = new Random();
var prices = Observable.Generate(
5d,
i => i > 0,
i => i + rand.NextDouble() - 0.5,
i => i,
i => TimeSpan.FromSeconds(0.1)
);
Woah! Lets go through this slowly.
- The first parameter (5d) is the initial seed or starting price for our observable sequence.
- Then we have a break condition (i > 0). We are effectively saying, keep generating prices while the price is greater than zero. If the price drops to zero we can assume that the company is bankrupt.
- Then we define (i + rand.NextDouble() – 0.5) how we’d like the price to be incremented, by a random value between –0.5 & 0.5.
- You can then optionally transform the notification, we are not using this feature (i => i).
- Finally we can supply a time interval TimeSpan.FromSeconds(0.1), telling Generate when we’d like to yield the next iteration in our observable sequence. We could randomize this as well, I’m just going to generate a new price every 0.1 seconds.
Essentially Generate is a parameterised factory method that allows you to “corecursively” define an observable sequence. The function parameters passed into the method define the behaviour (the single next step) of the observable sequence, much like a mathematical series. In functional programming this concept is known as “anamorphism” or “unfold”. Generate is anamorphism for observables sequences!
If you drop the code in LINQPad, you should see an output like this.

If you don’t have LINQPad, you could write a small console application to test this out.
Buffer
So now that we have some test data to work with lets look at how we can calculate the Open, High, Low & Close (OHLC) prices. Last August I did this using Rx’s Buffer operator. Reactive Extensions has evolved significantly since then. Here is a quote from my old post.
“Rx handles this type of problem perfectly via the “Buffer” operator.”
We had some code similar to this;
from buffer in prices.Buffer(TimeSpan.FromSeconds(1))
select new
{
Open = buffer.First(),
High = buffer.Max(),
Low = buffer.Min(),
Close = buffer.Last()
}
You can drop this in LINQPad with our test data.

This works, however in retrospect, “perfectly” was a little far from the truth. Lets take a close look at how buffer works…
As we subscribe to the query, the buffer operator will create a list. All notifications from the underlying source will be placed into this list until the timer elapses. At this point, the observer will be given the list containing all the notifications. We can then interact with this list, in this example, to calculate our OHLC values. This might help you understand how the buffer operator works. I’d recommend pasting this code into LINQPad and having a play around with it.
Code
var source = new Subject();
var timer = Observable.Interval(TimeSpan.FromSeconds(1));
var buffer = source.Buffer(() => timer);
buffer.Subscribe(Console.WriteLine);
source.OnNext('a');
source.OnNext('b');
source.OnNext('c');
Thread.Sleep(1100);
source.OnNext('d');
source.OnNext('e');
source.OnNext('f');
source.OnCompleted();
Pictures

This approach is fine when we have three notifications per 1 second interval, but what will happen if we have a volatile price and say maybe a 1 minute interval? Our buffer is completely unbounded. This could lead to our short lived notifications being elevated into the generation 2 heap. If the buffer gets big enough, this could even result in a large object heap allocation.
Buffer has its uses but in this case, our open, high, low & close computation, doesn’t need all the values at once. We could perform the same calculation by stashing the first and last values (open & close) and tracking the min & max (high and low) values over the specified interval. What we need is an operator that allows us to react to the values over a window of time.
Window
Last December the Rx Team gave us a Christmas present focused around “Programming Streams of Coincidence”. There are some pretty powerful tools in there. If you are interested Lee Campbell has a post covering this family of operators. For this problem, we are interested in Window, which really is perfect for calculating OHLC over an observable stream of prices. Buffer & Window have a few different overloads, but these are the two we are talking about here;
IObservable> Buffer(this IObservable source, TimeSpan timeSpan)
IObservable> Window(this IObservable source, TimeSpan timeSpan)
So how do these two operators differ? Buffer creates a list at each window opening and passes it to the observer when the window closes. In contrast the Window operator creates a subject at each window opening and passes it to the observer immediately. The subject acts as a conduit, allowing the operator to pipe each notification to the observer until the window closes. Here is the Buffer marble diagram again, this time along side Window;

Window is more powerful than Buffer as the observer can decide how to process the notifications within the context of the window. This can be achieved by applying SelectMany to the Window operator.
Query Comprehension Syntax
from window in source.Window(timeSpan)
from ? in window.?
select ?
Lambda Syntax
source.Window(timeSpan).SelectMany(window => ?, (x, ?) => ?)
Pictures

Interestingly the Buffer overload we’ve been discussing, is actually implemented using this technique. Lets use this as an example;
Query Comprehension Syntax
// Implement Buffer using Window
public static IObservable> Buffer(this IObservable source, TimeSpan timeSpan)
{
// Transform IObservable> -> IObservable>
return
from window in source.Window(timeSpan)
from buffer in window.ToList()
select buffer;
}
Lambda Syntax
source.Window(timeSpan).SelectMany(window => window.ToList())
Pictures

You can write any query you want over the window observable. Maybe the observer is only interested in the last value, this is semantically equivalent to Sample;
Query Comprehension Syntax
// Implement Sample using Window
public static IObservable MySample(this IObservable source, TimeSpan timeSpan)
{
return
from window in source.Window(timeSpan)
from last in window.TakeLast(1)
select last;
}
Lambda Syntax
source.Window(timeSpan).SelectMany(window => window.TakeLast(1))
Pictures

Aggregate
OK so we have a mechanism that effectively divides a stream of events into smaller streams of events based on windows of time. All we need is a query that we can run over each observable window. Remember Buffer was implemented using ToList? Well ToList is actually implemented using Aggregate!
In fact all sorts of things can be implemented using Aggregate. Remember the Generate (anamorphism) method we used to create our test data? Well it’s actually the dual to Aggregate! While Generate takes a seed and applies some functions to produce a series of notifications, Aggregate takes a series of notifications and recursively applies an accumulator function, until it reaches the end of the sequence, at which point it yields a result. Aggregate is “catamorphism or fold” for observable sequences!

We are going to use Aggregate to compute the OHLC values for each Window of prices. Before we do that lets just make sure everyone is comfortable.
Aggregate Method Signature
IObservable Aggregate(
this IObservable source,
TAccumulate seed,
Func accumulator)
Marble Diagram

Confused? Scared? Don’t be…
Lets look at an example. Here is Sum implemented using Aggregate.
Sum
Observable.Range(1,3).Aggregate(0, (sum, value) => sum + value)

As I mentioned earlier, ToList is also implemented using Aggregate.
ToList
Observable.Range(1,3).Aggregate(new List(), (list, value) =>
{
list.Add(value);
return list;
})

If you’ve not grokked it, try implementing some other basic operators like Min & Max.
OHLC (Window + SelectMany + Aggregate)
So can we use Aggregate for our OHLC calculations? Lets start with the easy stuff by defining the fields we’ll need to keep track of these four values.
class OHLC
{
public double? Open;
public double? High;
public double? Low;
public double Close;
}
Now we just need a function that takes the current values & a prices and produces the new values.
// (TAccumulate, TSource) -> TAccumulate
static OHLC Accumulate(OHLC state, double price)
{
// Take the current values & apply the price update.
state.Open = state.Open ?? price;
state.High = state.High.HasValue ? state.High > price ? state.High : price : price;
state.Low = state.Low.HasValue ? state.Low < price ? state.Low : price : price;
state.Close = price;
return state;
}
If we bring this together with Window, SelectMany & Aggregate, we’ve now got a query that takes a stream of prices, splits it into windows and calculates OHLC values.
from window in prices.Window(TimeSpan.FromSeconds(1))
from result in window.Aggregate(new OHLC(), Accumulate)
select result

For readers who are not using LINQPad, I’ve written a console application. You can download it here;
Console Application Code
using System;
namespace ConsoleApplication124
{
using System.Reactive.Linq;
class Program
{
static void Main()
{
var rand = new Random();
var prices = Observable.Generate(
5d, i => i > 0, i => i + rand.NextDouble() - 0.5, i => i, i => TimeSpan.FromSeconds(0.1));
var query = from window in prices.Window(TimeSpan.FromSeconds(1))
from result in window.Aggregate(new Ohlc(), Accumulate)
select result;
query.Subscribe(Console.WriteLine);
Console.ReadLine();
}
class Ohlc
{
public double? Open;
public double? High;
public double? Low;
public double Close;
public override string ToString()
{
return (new { Open, High, Low, Close }).ToString();
}
}
static Ohlc Accumulate(Ohlc current, double price)
{
current.Open = current.Open ?? price;
current.High = current.High.HasValue ? current.High > price ? current.High : price : price;
current.Low = current.Low.HasValue ? current.Low < price ? current.Low : price : price;
current.Close = price;
return current;
}
}
}
Plotting The Results
Finally, we’re going to plot these results using the charting controls that come with .NET 4.0. Unfortunately/Strangely these controls are only available for Windows Forms developers. It appears that they will be available in a future version of WPF, there is a preview release available here. Alternatively there are lots of 3rd party charting packages that offer similar functionality. I’ll try these out in a future post. For now I’m going to use the Windows Forms controls, conceptually there shouldn’t be much of a difference.
First lets prepare the project.
1. Create a new Windows Forms project.

4. Add references to Reactive Extensions.

Your references should now look something like this;

3. Drop a Chart control onto the form.

4. I’m going to get rid of the Legend.

Click remove.

The Code
In the introduction I talked about two different chart types. Both are supported by this control library.
series.ChartType = SeriesChartType.Candlestick;
series.ChartType = SeriesChartType.Stock;
For testing purposes, I’m going to set the resolution of the time axis so that it will work with 1 second intervals. A window that small isn’t useful in the real world, the smallest I’ve seen is 1 minute, but we want to see some results straight away.
series.XValueType = ChartValueType.Time;
var area = chart1.ChartAreas[0];
area.Axes[0].Title = "Time";
area.AxisX.LabelStyle.IntervalType = DateTimeIntervalType.Seconds;
area.AxisX.LabelStyle.Format = "T";
Finally we need to subscribe to our query & test data and populate the chart.
query.ObserveOn(this).Subscribe(x => series.Points.AddXY(DateTime.Now, x.High, x.Low, x.Open, x.Close));
If you put all this code in the form’s constructor and run the project, you should have something like this;
using System;
using System.Windows.Forms;
using System.Reactive.Linq;
using System.Windows.Forms.DataVisualization.Charting;
namespace Chart
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Configure the chart
var series = chart1.Series[0];
series.ChartType = SeriesChartType.Candlestick;
series.XValueType = ChartValueType.Time;
var area = chart1.ChartAreas[0];
area.Axes[0].Title = "Time";
area.AxisX.LabelStyle.IntervalType = DateTimeIntervalType.Seconds;
area.AxisX.LabelStyle.Format = "T";
// Test prices
var rand = new Random();
var prices = Observable.Generate(5d, i => i > 0, i => i + rand.NextDouble() - 0.5, i => i, i => TimeSpan.FromSeconds(0.1));
// OHLC query
var query =
from window in prices.Window(TimeSpan.FromSeconds(1))
from ohlc in window.Aggregate(new OHLC(), Accumulate)
select ohlc;
// Subscribe & display results
query.ObserveOn(this).Subscribe(x => series.Points.AddXY(DateTime.Now, x.High, x.Low, x.Open, x.Close));
}
class OHLC
{
public double? Open;
public double? High;
public double? Low;
public double Close;
}
static OHLC Accumulate(OHLC current, double price)
{
current.Open = current.Open ?? price;
current.High = current.High.HasValue ? current.High > price ? current.High : price : price;
current.Low = current.Low.HasValue ? current.Low < price ? current.Low : price : price;
current.Close = price;
return current;
}
}
}
Run the application;

Additionally we can apply a suitable colour scheme to the chart;
// Colours
chart1.BackColor = Color.Black;
chart1.ChartAreas[0].Axes[0].LineColor = Color.LimeGreen;
chart1.ChartAreas[0].Axes[0].TitleForeColor = Color.LimeGreen;
chart1.ChartAreas[0].AxisX.MajorTickMark.LineColor = Color.LimeGreen;
chart1.ChartAreas[0].AxisX.LabelStyle.ForeColor = Color.LimeGreen;
chart1.ChartAreas[0].Axes[1].LineColor = Color.LimeGreen;
chart1.ChartAreas[0].Axes[1].TitleForeColor = Color.LimeGreen;
chart1.ChartAreas[0].AxisY.MajorTickMark.LineColor = Color.LimeGreen;
chart1.ChartAreas[0].AxisY.LabelStyle.ForeColor = Color.LimeGreen;
chart1.ChartAreas[0].BackColor = Color.Black;
series["PriceDownColor"] = "Red";

Download
You can get a working demo application here. As discussed I will provide a WPF based solution soon.
I’ve tried to make this article useful for both readers that know Rx but nothing about finance, or know finance but are not familiar with Rx. I’m not sure if it really works so I’m interested to hear feedback from both camps.
More soon.